Das Kursprogramm RAIL-DATA-SCIENCE besteht im Jahr 2023 aus folgenden Teilen:
- Vorkurs (zweistündiges Online-Seminar) am 23. 05. 2023 >>> Tickets für den Vorkurs
- Hauptseminar (zweitägiges Webinar) am 12. – 13. 06. 2023 >>> Tickets für das Hauptseminar
- Follow-Up-Termin (Online-Fragestunde) Termin nach Absprache
Der BAHNVERBAND möchte die DIGITAL-KOMPETENZ seiner Mitglieder fördern und bietet für persönliche Vereinsmitglieder alle drei Kursteile KOMPLETT KOSTENFREI an. (*, **)
* Nur im Jahr 2023 – Ansonsten kostet der Vorkurs 100 Euro und das Hauptseminar 499 Euro
** Nur für persönliche Mitglieder mit ungekündigter Mitgliedschaft
VORKURS am 23. Mai 2023
RAIL-DATA-Grundlagen / VORKURS
(Vorkurs / Online-Einführungsmodul mit Prof. Dr. Raphael Pfaff)
RAIL-DATA — Vorkurs und methodische Grundlagen
- Termin: 23.05.2023
- Uhrzeit: 15:15 – 18:15 Uhr
- Referent: Prof. Dr. Raphael PFAFF
- Motivierung: „Viele Experten mit konventioneller Ausbildung im Bahnbereich sind nur wenige Schritte vom Einstieg in die mächtige Welt von BIG DATA und ARTIFICAL INTELLIGENCE entfernt. Mit dem Online-Seminarangebot überbrücken wir diese Lücke und vermitteln die heutzutage erforderlichen Methodenkenntnisse. Im Seminar werden praxisnahe Beispiel-Daten aus dem Bahnbereich verwendet, analysiert und visualisiert.“
- Seminarangebot: Zweistündiges Einführungssession per Webinar / „Schnupper-Seminar“ – Kostenfrei!
- Vorkurs zur thematischen Einführung in die Thematik von RAIL DATA SCIENCE (d.h. BIG DATA und KÜNSTLICHE INTELLIGENZ) sowie zur methodischen Vorbereitung (Installationsanleigung für die kostenlose Programmumgebung PYTHON). Der zweistündige VORKURS wird ebenso wie das zweitägige HAUPTSEMINAR sowie der optionale FOLLOW-UP-TERMIN von Prof. Dr. Raphael PFAFF (FH Aachen) als ONLINE-Veranstaltung angeboten.
- Die Grundlageneinheit zum Umgang mit RAIL-DATA („VORKURS“) besteht hauptsächlich aus dem Einstieg in die AI-relevante Software-Umgebung von PYTHON.
- Teilnehmer erfahren in einer kompakten – zweistündigen – Einführungseinheit (per Online-Webinar), wie man die kostenlose Open-Source-Softwarepakete von PYTHON auf dem eigenen Rechner zum Laufen bringt.
- Dies wird im zweitägigen HAUPTSEMINAR benötigt, um die Beispielaufgaben auf dem eigenen Computer bearbeiten zu können.
- Schließlich wird einge Wochen nach dem Hauptseminar noch ein optionaler Follow-Up-Termin angeboten, um die praktischen Übungen bzw. eigene Data-Science-Projekte zu besprechen.
SEMINARINHALTE – Was erwartet die Teilnehmer im VORKURS?
- Kurze Einführung in RAIL-DATA-SCIENCE sowie methodische Grundlagen (PYTHON).
- Die Teilnehmer des Webinars erfahren in einem rd. zweistündigen Vorkurs, wie man die KOSTENLOSE Open-Source Software „PYTHON“ ganz einfach auf dem eigenen Compter / Notebook installieren kann.
- Die mittlerweile weltweit relevante Programmiersprache für den Umgang mit BIG DATE ist „PYTHON“. PYTHON ist eine dynamische Programmiersprache mit hohem Funktionsumfang, die zudem für Einsteiger sehr schnell zu erlernen ist. Teilnehmer des Einführungsmoduls haben zum Ende des Vorkurses PYTHON auf dem eigenen Compter / Notebook und erhalten so die Möglichkeit, die Welt von DATA ANALYTICS und ARTIFICIAL INTELLIGENCE auf dem eigenen Rechner zu erkunden und somit die Chance, eigene Aufgabenstellungen auf dem eigenen Computer zu lösen.
- PYTHON passt perfekt zum Umgang mit RAIL DATA. Rail-Data-Science anhand der Module ist dann
Organisatorische Hinweise / Anmeldung:
- Seminarformat: Online-Seminar (kurzer Vorkurs; ca. 2 Stunden als Einführungswebinar für Einsteiger („Schnupper-Termin“):
- Anmeldehinweis und einmalige Sonderkonditionen für Rail-Data-Science 2023: Für persönliche Mitglieder im Bahnverband e.V. wird im Jahr 2023 sowohl der VORKURS als auch das HAUPTSEMINAR >>> KOMPLETT KOSTENFREI <<< angeboten.
- Der BAHNVERBAND möchte damit einen starken Beitrag zur KARRIEREFÖRDERUNG und zum ERWERB von DIGITAL-KOMPETENZ leisten.
- Persönliche Mitglieder des BAHNVERBANDES das komplette Kursprogramm (Vorkurs für 0 Euro (statt 100 Euro)) sowie alle Module des Hauptseminars (0 Euro statt 499 Euro)) KOSTENFREI buchen. Ersparnis: 599 Euro – (Dies entspricht rd. dem ZWÖLFFACHEN des Mitgliedsbeitrages).
- Nota bene: Dieses Super-Sonderangebot gilt nur im Jahr 2023 und nur für persönliche Mitglieder des BAHNVERBANDES e.V. mit ungekündigter Mitgliedschaft.
TEILNEHMERTICKET für den VORKURS im Online-Ticketshop buchen:
Preis für diese Einführungeinheit per Online-Webinar:
Standardpreis: 100,00 €
Ticketshop >>> TEILNEHMERTICKET zum STANDARD-PREIS
Preis für MITGLIEDER im Bahnverband:
Mitgliedersonderpreis: 0,00 EURO (Standardpreis: 100 € – Rabatt von 100 €)
Ticketshop >>> TEILNEHMERTICKET zum Mitglieder-Sonderpreis
MITGLIEDSCHAFT MIT MEHRWERT!
Persönliche Mitglieder des BAHNVERBANDES e.V.* erhalten für dieses besondere Online-Seminar einen Rabatt in Höhe von 100 EURO und nehmen quasi kostenfrei teil! (Es fallen lediglich die eigenen Verbindungskosten (abhängig vom jeweiligen Internetzugang) an, um an der angebotenen Videokonferenz teilnehmen zu können.)
- Informationen zur Mitgliedschaft im Bahnverband >>> MITGLIEDSCHAFT
* Dieses Super-Sonderangebot gilt selbstverständlich nur bei ungekündigter Mitgliedschaft!
#
HAUPTSEMINAR am 12. – 13. Juni 2023
Intensivseminar zur Daten-Analyse für Bahn-Anwendungen
Nehmen Sie am nächsten Seminar vom 16. – 17. Dezember 2024 teil!
Zweitägiges Webiner plus Follow-up-Sprechstunde per VIDEO-KONFERENZ.
STANDARDPREIS für die zweitägige Weiterbildung: 450,– Euro
Der BAHNVERBAND e.V. möchte den Erwerb von DIGITAL-KOMPETENZ fördern und so die die GESCHÄFTLICHE KOMPETENZ von Unternehmen ausweiten und zudem die KARRIERECHANCEN einzelner Mitarbeiter erhöhen.
 .
.
DOWNLOAD Seminarprospekt rail-data-science.pdf
Sie können AB SOFORT sich über den WebShop anmelden,
indem Sie Ihr Ticket für diese Weiterbildung einfach online buchen:
Seminarkonzept
Warum ist das Thema DATA SCIENCE im Bahnbereich wichtig?Wie oft hören wir „Daten sind das neue Öl“ – wir alle haben Öl in der Organisation, doch nur die wenigsten fördern es. Die Nutzung von Daten hilft dem Unternehmen, reifer zu werden, indem es Entscheidung weg vom Bauch auf die Sachebene hebt und Kunden, Behörden sowie Lieferanten mit starken Argumenten überzeugt. Moderne Werkzeuge machen den Data Science-Prozess einfach handhabbar, damit kann ein Empowerment durch Datennutzung in der Organisation an vielen Stellen einfach umgesetzt werden.. Warum sollten Sie an diesem Seminar teilnehmen? – Was haben Sie davon?(1.) Sie haben Daten und möchten Sie schnell und einfach nutzen. (2.) Sie benötigen ansprechende Visualisierungen, Modelle oder sogar eine einfache WebApp für Analysen, Berichte oder den Betriebsablauf. (3.) Sie möchten ihren digitalen Werkzeugkasten um neue Tools erweitern, eventuell sogar um bestehende Applikationen zukunftsfähig zu machen.. |
Rail Data Science ist ein Modul der Brückenseminare, die helfen, ihr vorhandenes Fachwissen auf neue Tools zu portieren – als kompakte Einheiten mit sofortigem Effekt.
Das Seminar wird online und weitgehend asynchron angeboten, mit Lehrtexten, Videos und ihrer praktischen Umsetzung. Damit können sie das komplette Seminar-Programm in den zwei geplanten Tagen absolvieren, sind aber zeitlich flexibel in der Auswahl der Module, die für Sie von Interesse sind. Der Referent – Prof. Dr. R. PFAFF – steht in mehreren Online-Sprechstunden für individuelle Fragen zur Verfügung.
Die Seminarteilnahme setzt eine Installation des Anaconda-Pakets auf dem Rechner der Teilnehmenden voraus, alternative Wege über google Colab oder Binder werden ebenfalls angeboten. Die (optionale) Entwicklung der WebApp kann nur auf dem eigenen Rechner erfolgen und setzt Python (auf den meisten Systemen bereits vorhanden) voraus.
Wie man die Programmiersprache PYTHON auf dem eigenen Rechner installiert, wird in einem sog. VORKURS vermittelt. >>> rail-data-grundlagen
Seminarinhalte
Im Seminar wird viel „gemacht“ und weniger gelehrt. Dadurch kommt jede Teilnehmerin und jeder Teilnehmer mit einem gut gefüllten Koffer an neuen Werkzeugen und bereits implementierten Beispielen zurück. Diese Beispiele können dannn in der Praxis unmittelbar eingesetzt werden.
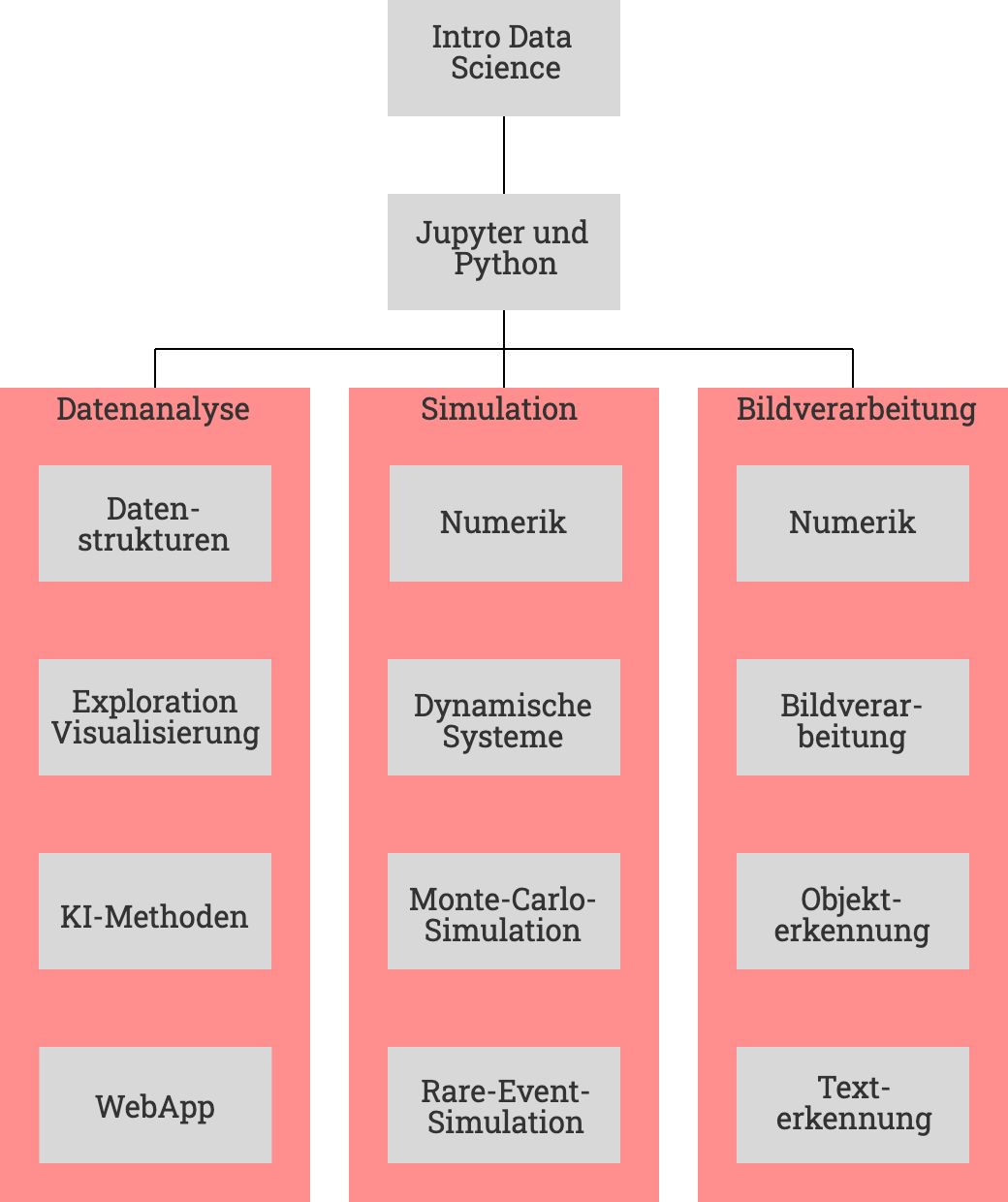
Damit die unmittelbare Anwendbarkeit noch stärker in den Vordergrund rückt, kann das Seminar modular absolviert werden. Wir empfehlen, je nach Interesse und Bedarf, eines (oder mehrere) der drei Muster-Programme:
- Grundlagen: Alle Programme basieren auf Python und Jupyter Notebooks, bevor wir damit beginnen gibt es eine kurze Einführung in Data Science. Alle verwendeten Bibliotheken sind frei und Open Source, also im Unternehmenskontext ohne direkte Investition nutzbar.
- Datenanalyse: Sie wollen Daten aus ihrem Unternehmen und aus anderen Quellen integrieren? Sie wollen datenbasierte Abläufe automatisieren und in ihrer Organisation verteilt nutzbar machen? Dann lernen sie in diesem Programm die Daten zur erforschen, effiziente Datenhaltung (auch für Big Data geeignet) sowie Methoden der künstlichen Intelligenz kennen und können sie anwenden. Optional setzen sie das Erlernte in einer WebApp um, die sie unternehmensweit bereitstellen können.
- Simulation: Sie müssen spezialisierte Simulationen durchführen, evtl. bestehende Routinen fit für die Zukunft machen? In diesem Programme lernen sie, Aufgaben der numerischen Mathematik in Python umzusetzen, dynamische Systeme zu simulieren sowie Monte-Carlo- und Rare-Event Simulationen, zum Beispiel für Sicherheitsbetrachtungen, kennen und anwenden.
- Bildverarbeitung: Sie müssen visuelle Daten, zum Beispiel aus automatischen Inspektionsanlagen oder papierbasierten Prozessen, verarbeiten? Dieses Programm führt, basierend auf der numerischen Mathematik, in Bilderfassung und -verarbeitung ein, um sie dann Objekte und Texte automatisiert erfassen und verarbeiten zu lassen.
Kurzbeschreibung der Module
Datenanalyse
- Datenstrukturen: Ohne Datenstrukturen keine Algorithmen. In diesem Modul geht es um tabellenartige Datenstrukturen, die wir mit der Bibliothek Pandas nutzen.
- Exploration und Visualisierung: Wir importieren Daten aus lokalen und Cloud-Quellen, stellen sie graphisch dar und untersuchen mit effizienten Tools ihre Eigenschaften. Dazu setzen wir u.a. Matplotlib, Seaborn und Plotly ein.
- KI-Methoden: Künstliche Intelligenz ist in aller Munde. Wir nutzen Scikit-Learn, eine sehr zugängliche KI-Bibliothek um Methoden wie Clustering, Support-Vector-Machines und Autoencoder auszuprobieren.
- WebApp: Mit den richtigen Tools ist es leicht geworden, die zuvor entwickelten Lösungen nutzbar zu machen. In diesem Modul entwickeln wir eine erste WebApp mit Flask und zeigen den Weg in die Cloud.
Simulation
- Numerik: Die Numerik-Bibliothek NumPy macht Berechnungen einfach und elegant. Wir setzen einige Beispiele um und lernen damit die Konzepte und Strukturen kennen.
- Dynamische Systeme: Oft müssen dynamische Systeme und regelungstechnische Strukturen simuliert werden. Wir nutzen PyControl für Simulationen linearer dynamischer Systeme und Reglereinstellung.
- Monte-Carlo-Simulationen: Viele Prozesse laufen zufällig ab. In diesem Modul lernen wir, den Zufall zu simulieren und damit Vorhersagen über das Ergebnis, zum Beispiel nach Änderung von Prozessvariablen, zu treffen.
- Rare-Event-Simulation: Zufallsprozesse mit seltenen Events kommen im System Bahn an vielen Stellen vor, beispielsweise bei Bremskurven. Die speziellen Ansätze für Rare-Event-Simulation werden wir in NumPy umsetzen.
Bildverarbeitung
- Numerik: Die Numerik-Bibliothek NumPy macht Berechnungen einfach und elegant. Wir setzen einige Beispiele um und lernen damit die Konzepte und Strukturen kennen.
- Bildverarbeitung: In diesem Modul lernen wir, Bilddaten zu erfassen, grundlegende Transformationen durchzuführen und sie anzuzeigen und zu speichern. Dazu nutzen wir OpenCV, die Grundlage für viele Bildverarbeitungsaufgaben bis hin zu autonomem Fahren.
- Objekterkennung: Das Erfassen, Markieren, Zählen und Lokalisieren von Objekten in den Bilddaten gehört zu den grundlegenden Aufgaben, die wir hier mit analytischen Methoden und vortrainierten Filtern lösen.
- Texterkennung: Viele Prozesse in Unternehmen nutzen papiergebundene Formulare. In diesem Modul lesen wir Bilder dieser Dokumente ein und extrahieren die Texte von Interesse mit Hilfe von PyTesseract, um sie automatisiert nutzbar zu machen.
- Deep-Learning – Wertvolle Hinweise zum Bau von selbstlernenden Systemen auf dem eigenen Rechner.
Referent
Prof. Dr. Raphael PFAFF
Raphael Pfaff war nach einem Studium der Mechatronik, Mathematik und Regelungstechnik für Siemens und Faiveley Transport, zuletzt als Konstruktionsleiter, tätig. Er betrachtet sich eher als angewandten Mathematiker mit ganz guter Technikausbildung und hat daher häufig an der Schnittstelle zwischen Technik und Mathematik bzw. Data Science gearbeitet. Seit 2014 ist er Professor für Schienenfahrzeugtechnik an der FH Aachen. Seine Forschungsschwerpunkte liegen im Bereich Digitalisierung und Automatisierung im Güterverkehr.

Prof. PFAFF bei der Expertentagung DIGITAL-RAIL.
![]()
![]()
Prof. PFAFF mit einer Exkursionsgruppe von der FH Aachen.
![]()
![]()
Prof. PFAFF und Vereinsgeschäftsführer SCHULZ auf der Bühne des Karriereforums (während der InnoTrans).
Teilnehmerstimmen
|
Fragen / Kontakt
- Inhaltliche Fragen >>> Kontakt zum Seminarleiter >>> Prof. Dr. PFAFF
- Organisatorische Fragen >>> Kontakt zum Seminarveranstalter



